当然,让我们继续用最通俗易懂的方式来了解这些设置选项。
这些设置选项就像是你为你策略量身定做的“规则”,它们决定了你的 Alpha 模型在什么条件下运行。
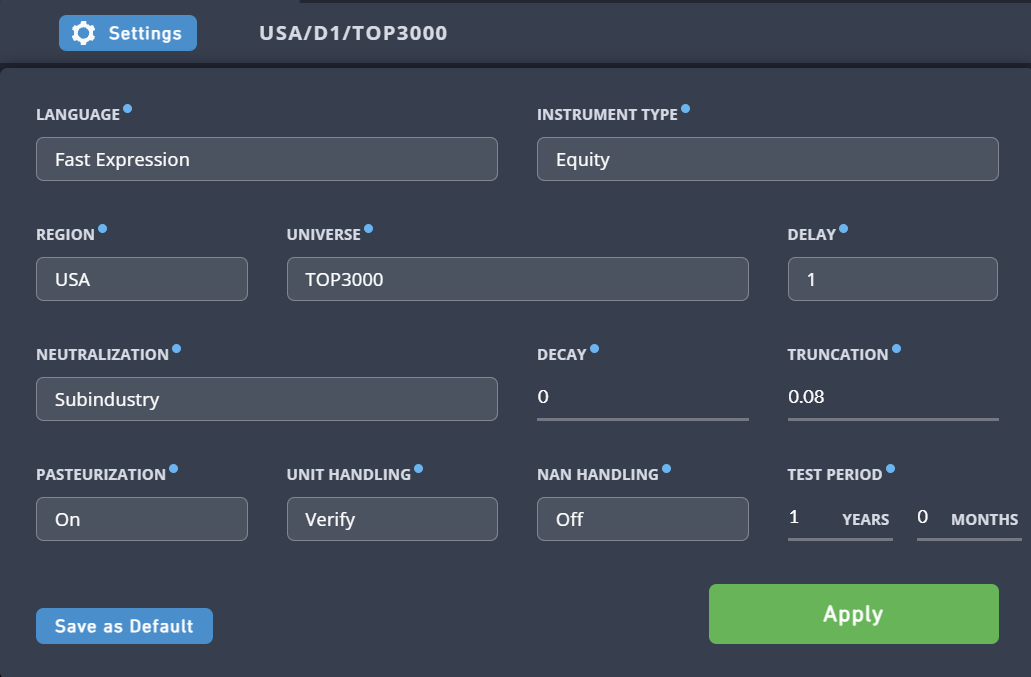
这个很简单。你只需要知道,你使用的语言叫 Fast Expression,这是一种专门用来写量化公式的简化语言。你目前只能用它来模拟股票(Equity)。
这个设置决定了你的模型要分析哪个国家或地区的股票。
- 目前: 你只能选择美国(United States)。
- 未来: 当你成为更高阶的用户(顾问)后,你就能解锁更多地区,比如中国、日本、欧洲等,甚至可以同时模拟全球的股票。
股票池是你进行模拟的“候选股票库”。它通常基于股票的**流动性(liquidity)**来筛选。
- 流动性可以简单理解为股票的交易活跃度。流动性越高,股票就越容易买卖,对我们来说越好。
- 你可以选择不同的股票池,比如 TOP 3000,这意味着你的模型将只在市场上交易最活跃的 3000 只股票中进行选择。选择不同的股票池会影响你的模型最终能抓住哪些机会。
这个设置决定了你的数据有多“新鲜”。
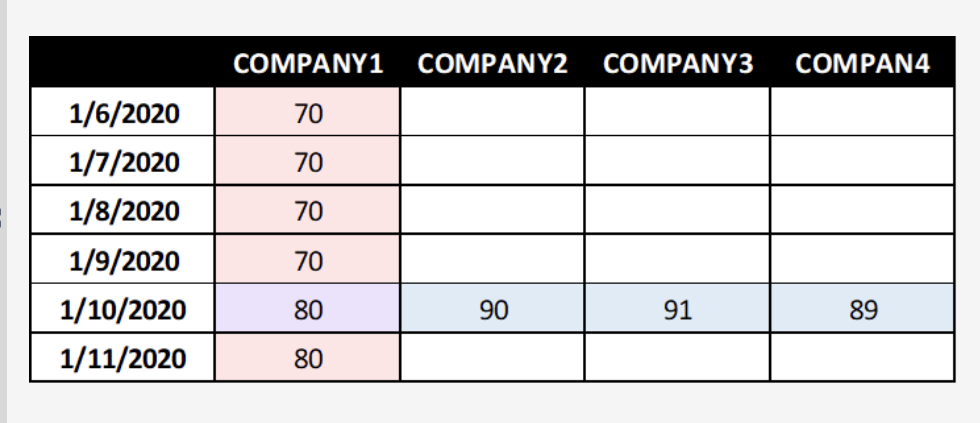
- 为什么会有延迟? 举个例子,你无法在当天市场收盘前就知道收盘价。所以,通常我们会用 Delay1,也就是用前一天的数据来预测今天。这是最普遍、最安全的做法。
Delay0:如果你想更“快”,可以用 Delay0,它使用当天市场收盘前的数据进行预测。但这更难,因为数据可能不完整,而且提交要求更严格。你可以简单理解为 Delay0 的信号更“快”,但需要你更谨慎地使用。
我们之前说过,通过多头-空头组合可以对冲掉大盘风险。但还有一种风险叫行业风险。
- 行业风险:想象一下,油价大涨,所有石油公司的股票都涨了,而所有航空公司的�股票都跌了。你的模型可能因此集中做多石油股,集中做空航空股。这导致你的策略过度依赖这两个行业的表现。
- 行业中性化: 解决办法是只在同一个行业内部进行中性化。比如,在石油行业内部,你做多涨得少的,做空涨得多的。在航空行业内部也一样。这样,你的策略就能排除掉行业整体涨跌的影响,只专注于行业内部的相对表现。
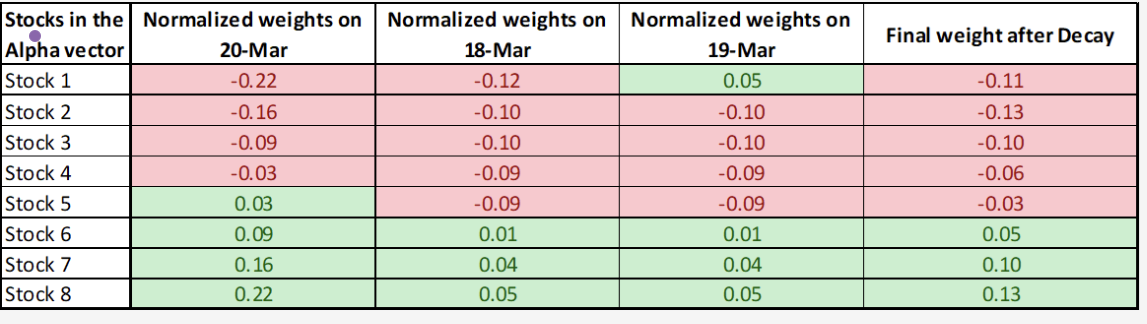
这个我们之前详细讲过,它决定了你的模型对历史数据的**“记忆”程度**。
- 高衰减值意味着你的策略变化会更平缓,交易更少,但可能会错过最新的信号。
- 低衰减值意味着你的策略变化会更激进,更及时地响应最新信号,但可能不够稳定。这是一个需要在稳定性和反应速度之间权衡的设置。
这个设置是为了防止你的资金过于集中在某一只股票上。
- 为什么需要截断? 有时你的 Alpha 模型可能会认为某只股票是“最好的”,然后把所有资金都压在这只股票上。这风险太高了。
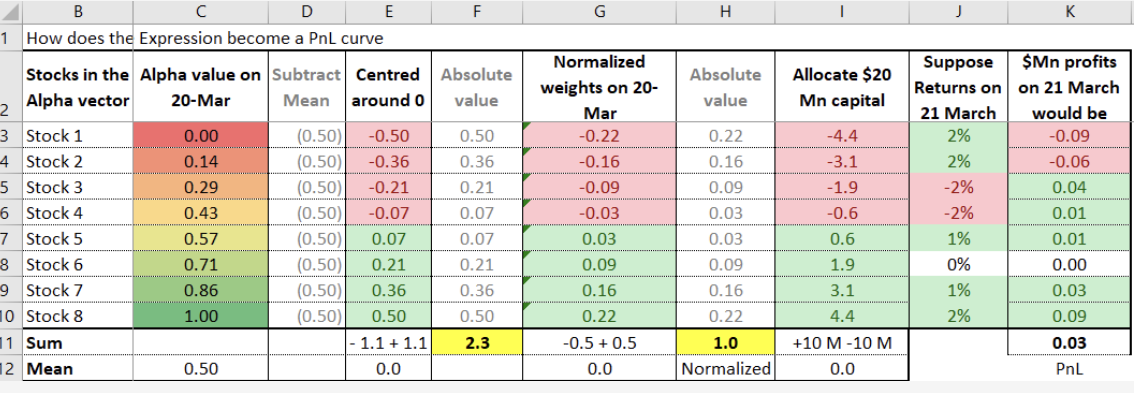
- 作用: 截断可以限制单只股票的最大仓位比例。比如,设置截断为 1%,那么无论你的模型多看好某只股票,你最多只能将 1% 的资金投资于它。这有助于分散风险,提高投资组合的稳健性。
- 巴氏杀菌法(Pasteurization):一个复杂的概念,你可以简单理解为,它决定了在计算时,是否把那些不在你选定股票池里的股票也考虑进来。
- 单位处理(Unit Handling):它会帮你检查数据单位是否匹配,并给出警告,但不会影响模拟结果。
- 缺失值处理(NaN Handling):当某些数据缺失时(NaN代表“不是一个数字”),这个选项决定是把它们当成 0 来处理,还是忽略它们。
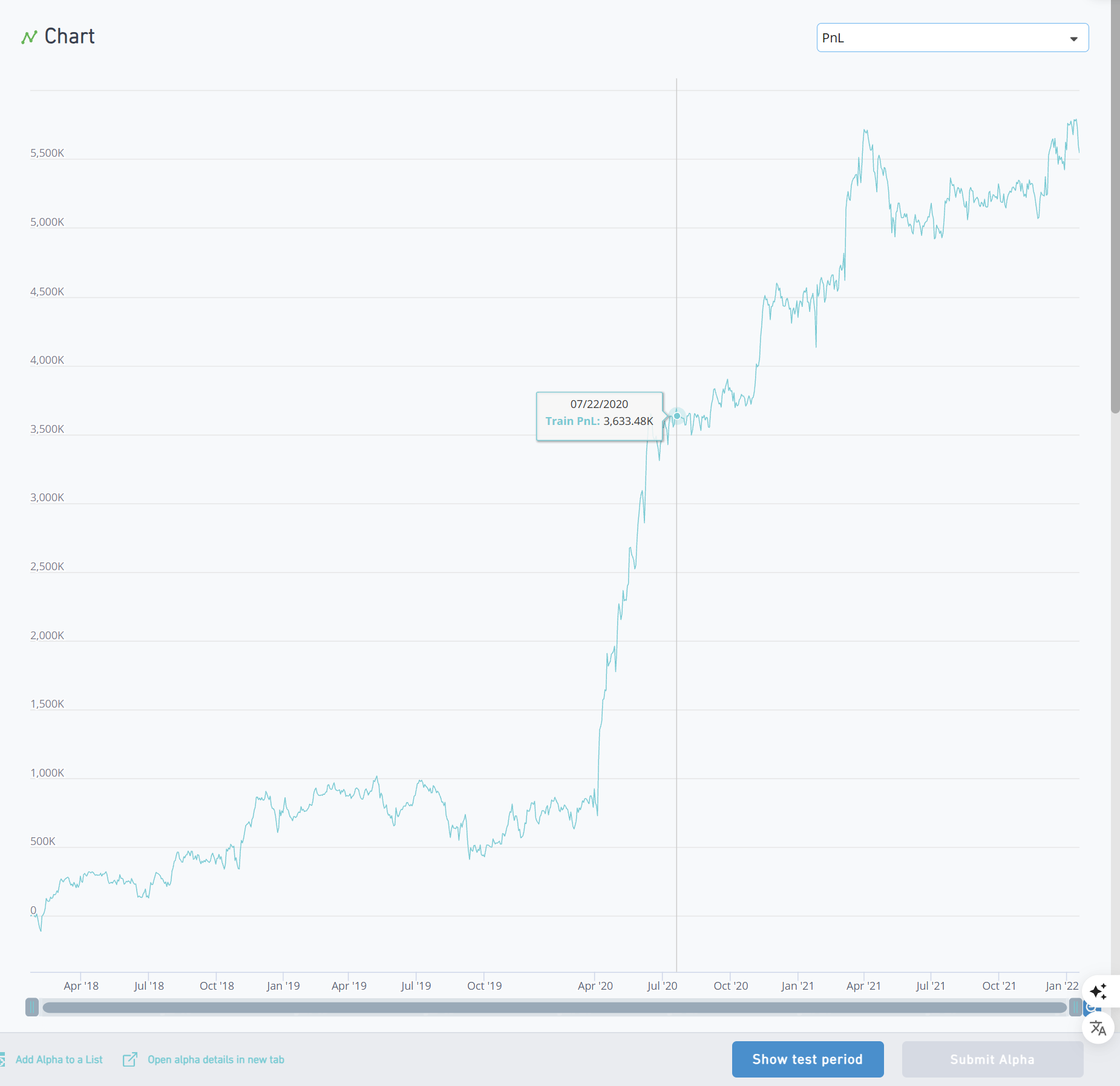
这是一个非常有用的功能,用于评估你的模型是否真的稳健。
- 如何使用? 你可以隐藏一部分模拟结果(比如最后一年)。在你看不到这部分结果的情况下优化你的模型。当你认为模型已经足够好时,再点击“显示测试周期”来看它在这段隐藏时间内的表现。
- 作用: 如果你的模型在隐藏期间的表现依然很好,那就说明它不是“过拟合”了历史数据,而是一个真正稳健、能预测未来的好模型。
在 BRAIN 平台上,你需�要的数据都已经被整理好了,并且有了特定的名字,这样你就可以像使用一个变量一样在你的公式中调用它们。你可以把整个数据系统想象成一个图书馆,它被分为三个层次:
- 数据集类别(Dataset Categories): 就像图书馆的大分类,比如“历史类”、“科学类”或“金融类”。
- 数据集(Datasets): 就像大分类下的具体书架。例如,“金融类”下面可能有“公司财报”书架和“股票价格”书架。
- 数据字段(Data fields): 就像书架上的一本本书,每一本都包含具体的数据。比如在“股票价格”书架上,你可能会找到一本叫做《收盘价》的书,里面就是每只股票每天的收盘价数据。
- 数据集类别(Dataset Categories): 这是最高层级的分类,将所有数据分为 17 个主要类别。比如,你可以在“基本面数据”(Fundamental)这个类别下找到公司的财报信息,或者在“价格/成交量数据”(PV)这个类别下找到股票的价格和成交量信息。
- 数据集(Datasets): 它们是按主题分组的数据集合。通常,它们的命名方式是在类别名后面加上数字,比如
PV1 或 fundamental6。
PV1:这个数据集包含了所有与股票价格和成交量相关的数据,比如开盘价、最高价、最低价、收盘价,以及 20 日平均成交量等。fundamental6:这个数据集则包含了公司财务报表中的各种详细数据,比如资产、资本和负债等。
- 数据字段(Data fields): 这是你真正要用的数据。它们以矩阵的形式存在,你可以直接用它们的名字在你的公式中调用。我们之前用过的
returns 就是一个数据字段,它包含了所有股票的回报率信息。
平台提供了一个专门的 “数据区”(Data Section) 来帮助你查找数据字段。
- 搜索功能: 你可以直接输入数据集或数据字段的名称进行搜索。
- 按类别浏览: 你也可以像逛图书馆一样,先从大的分类(数据集类别)开始,一步步找到你想要的数据。
重要提示:
在搜索之前,一定要先检查屏幕右上角的设置,确认你选择了正确的地区(Region)、延迟(Delay)*和*股票池(Universe)。因为不同的设置下,可用的数据字段可能会有所不同。
好的,我们继续用最通俗易懂的方式来理解这些“操作符”。
你可以把**操作符(Operators)**想象成工具箱里的各种工具。有了数据(原材料),你需要用这些工具来处理和转换它们,最终才能创建出你的 Alpha 模型。
这些操作符可以对数据进行各种运算,从简单的加�减乘除到复杂的统计分析,无所不包。
这些是最基础的工具,就像计算器一样。它们能让你对数据进行基本的数学运算,比如加、减、乘、除、取整等等。
这些工具用来做“判断”。它们会评估一个表达式是否成立,然后返回“真”(true)或“假”(false)。
- 在 BRAIN 中,“真”用 1 表示,“假”用 0 表示。
- 例如,你可以用它来判断“今天的收盘价是否高于昨天的收盘价”。如果是,结果就是 1;如果不是,结果就是 0。
这些工具专门用来处理时间序列数据,也就是与“过去”相关的数据。
- 核心功能: 它们让你能够回顾一只股票在过去一段时间内的表现。
- 举例:
ts_mean(x, d) 就是一个时间�序列操作符。它的作用是计算数据 x 在过去 d 天里的平均值。比如,你可以用它来计算一只股票过去 20 天的平均收盘价。
这些工具用来进行横向比较。它们会在同一个时间点上,比较所有股票的数据。
- 核心功能: 它们帮助你找出在某个时间点上,哪些股票相对表现更好或更差。
- 举例: 我们之前用过的
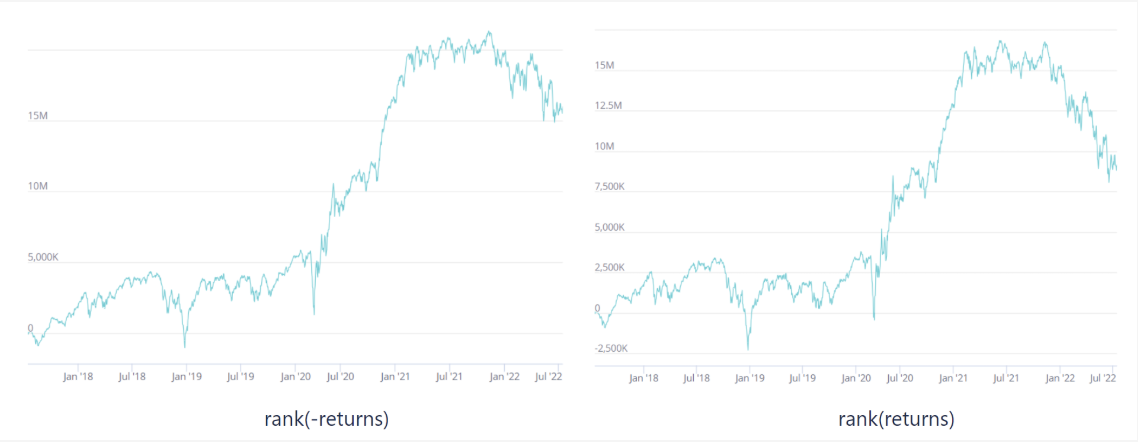
rank(x) 就是一个典型的横截面操作符。它会给所有股票的 x 值进行排名,并把结果转换为 0 到 1 的分数。
有些数据字段不是单个数值,而是包含多个值的“向量”。
- 核心功能: 这些操作符的作用是把一个包含多个值的向量,转换成一个能代表这个向量的单个值。
- 举例: 比如,一个数据字段可能包含了某只股票在一天内的所有交易价格。你可以用向量操作符,比如
mean()(求平均值)或 median()(求中位数),来得到一个代表当天价格的单一值。
这些操作符可以对数据进行特殊的转换。
有时候,数据字段会根据某些标准将公司进行分组,比如按照行业分类。
- 核心功能: 这些操作符允许你在这些分组内部进行操作。
- 举例: 你可以计算一个特定行业所有股票的平均值,或者在同一个行业内部进行中性化,从而消除行业整体涨跌的影响。