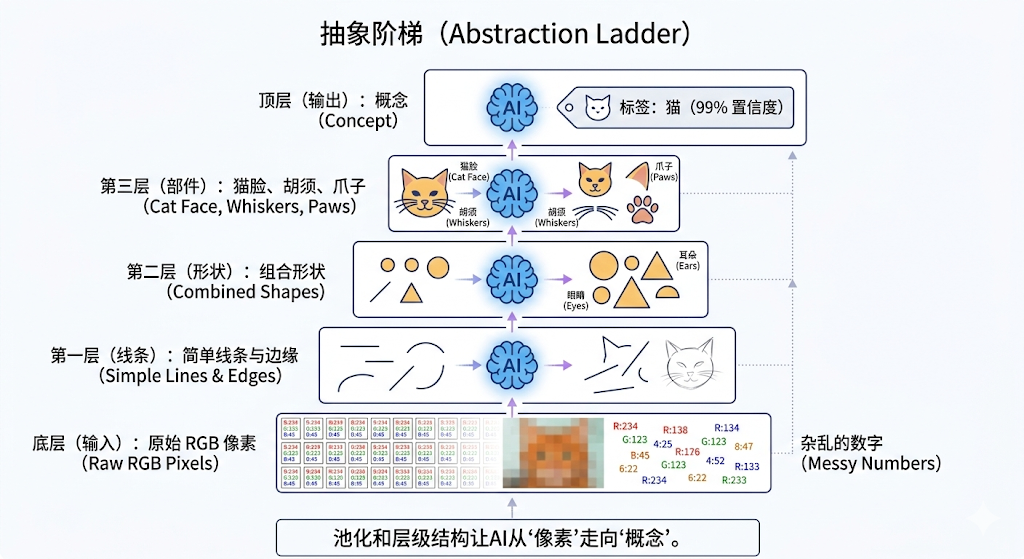
在上一章,我们见证了 SFT(指令微调)是如何把一头野兽驯化为得力助手的。 但全量微调(Full Fine-Tuning)那令人窒息的硬件成本,��一直死死卡着独立开发者和中小企业进场大练兵的咽喉。
试想一下,如果你想亲自下场微调一个目前最小标配尺寸(70亿参数 / 7B)的 LLaMA-3 模型。如果采用传统的全量 SFT 法,单单是它所需的显存峰值就能轻易冲破 80GB 大关。这意味着你必须去租用昂贵的 A100 或 H100 级别顶配运算旗舰。如果参数冲到 70B 级别,那么恭喜你,你的初创公司起步价就是四张高端计算卡起跳的庞大服务器集群。
有没有一种聪明讨巧的办法,不去碰那庞然大物本身,却依然能让它改头换面、拥有全新特质?在这个贫瘠的算力危机下,微软在 2021 年甩出了一篇让全球极客奉为圭臬的论文:LoRA。
1. 什么是 LoRA?(Low-Rank Adaptation)
全称拗口,我们俗称其为低秩微调。 它之所以被开源社区捧至封神的最高殿堂,是因为它优雅地解决了“既要改变模型思维,又绝没有任何一丝一毫闲钱去动用大机器算力阵列”的人性困境。
1.1 核心直觉:别动那块万年冰川
想象那个已经被大洋彼岸的巨头耗费上亿电费烧炼出厂的初始大模型,是一块重达万吨、复杂、坚硬无可撼动的远古大冰块(我们称之为:被冻结的主模型矩阵 )。
在鲁莽传统的全系统全量微调年代,工程师是直接拿起几万把滚烫炽热的刻刀(梯度更新状态记录),试图直接对这块原本好好的通体透明万吨冰块周身全方位地强行回炉重新融化重塑雕刻。这容易不仅把它的新造型给雕歪,更是由于操作规模动作太大,导致耗竭海量珍贵的显卡缓存资源。
而鸡贼的 LoRA 的底层哲学是:彻底拉起警戒线,绝不动原来那块万年基座主冰块参数分毫!
我们轻便灵巧地只在它那个冰块的边缘表面上,轻轻地用胶水外挂张贴两层薄若蝉翼的小贴纸(小旁路矩阵)。我们在漫长的特训时间里,绝不浪费任何一滴算力去更新大冰块内部那以几十亿计的主架构原始浮点;我们只集中所有极限集约火力,在这两张轻巧仅仅占区区几十兆大小的小小贴纸表面反复雕琢擦写我们要它学会的心法知识。
2. 降维魔法:为什么两张贴纸就够了?
你会质疑,大模型有几百亿参数,你只挂两个这么小的小贴纸小矩阵从旁“指点”,这只怪兽真的能学会艰深的心电图判读或者模仿出鲁迅文风吗?
这就要引出论文中最石破天惊的底层论断总结了:“过度参数化”与“低秩本征维度”的幻灭。
- 臃肿的高塔:别看原始模型那几百甚至千亿级别那吓死人的巨量数字大矩阵网,这些如浩瀚繁星的底层浮点权重里,有 90% 以上在应对具体的特定下游具象细分死任务(比如只用做代码续写填空,或只用于把长句翻译成日文)时,它们其实全都在偷懒无所事事地摸鱼休眠。能真正起到决定性关键一票作用的物理意义维度(即所谓的本征低秩降维),可能少得可怜。
- 降维重组的A/B小矩阵:LoRA 天才般地挂在原通道旁边狭长的两条“沙漏状”旁路通道矩阵(我们用数学物理代号 矩阵与 矩阵去称呼它们)。
- 先把庞大冗长长达 4096 宽度的信号粗暴降阶压缩至仅仅极可怜的 维度层宽漏斗(矩阵A)。
- 再把这个被浓缩的 8 维核心结晶,在下一个极近的路口重新还原放大变回拉升平坦的原版 4096 宽度体(矩阵B),并最终和主干线大冰块原本浩荡呼啸输出的大部队水流结果汇合相加在一起。
绝美公式: 输出结果
在这种漏斗结构的强迫压榨之下,模型被逼得无路可退,只能地把我们要教给它的那成千上万句鲁迅经典小说的文盲知识核心,极致压缩提炼凝结进那狭窄到仅有 8 个通道坑位的微小浮点骨血空间里。
3. LoRA 究竟有多神?
正是由于这种从主线上硬生生强行剥离出极速挂载件的惊艳思路,彻底引爆了随后的微调大跃进平民化大爆炸时代。
3.1 老百姓也能玩转的单卡微调与 QLoRA 极限压榨
显存被地生砍重创了绝大部分!由于主模型彻底断水断电被定格为全冻结冰状态,原先计算反向传播巨型梯度的庞大开销被近乎魔法般毫不留情地清零抹除抹杀! 原本硬刚需几十G显存的 LLaMA 模型,被巧妙逼进小旁路后,家用普通破风冷显卡也能在深夜轻松跑通。
更极致的工业核弹:QLoRA(量化 + LoRA) 如果你觉得单纯的 LoRA 还不够省,业界又祭出了一手刁钻的套路——QLoRA 极限压榨术。 它在挂载微小 A/B 旁路矩阵贴片之前,凶残地直接把那块庞大的基座大冰块抽调冻结,并且将其内部原本高精度的浮点数(FP16)直接暴力碾压砸碎降维成了扭曲粗糙的 4-bit 量化整型数据格式 (NF4)! 通过极大幅度榨干底座精度腾出来的空间配合 LoRA,这直接造成了一个科幻的后果:任何一个普通平民,只要拥有一张旗舰游戏卡甚至是高配 Mac 本,就能强行装载并私人微调一个 700 亿 (70B) 参数级开源通才大模型!
3.2 随拔随插的热更“变相皮肤包”
这甚至可能被引申为 LoRA 所造就的更伟大的颠覆物理形态:它不只是一种算力省钱作弊工具,它直接把 AI 应用彻底变成了一个个便于分发的几十兆大小的可切换的换装模块“皮肤卡带”!
那个几百 GB 重且愚笨巨大的底座 Base 模型永远雷打不动地静静独坐在沉重的云端内存条服务器母舰底托上安稳躺尸发光。 而我们在不同垂直行业接单时:
- 上午做法律案:我们可以毫秒之间极速地热插拔载入一个只有可怜区区 100MB 极小体重的“金牌政法律师专用高浓度 LoRA 权重压缩小贴纸”并挂载生效,大模型瞬间化身严谨字斟句酌法庭法官;
- 下午转做日漫机翻二次元生意:瞬间拔掉前任律师贴纸,重新卡扣合死载入精通御宅族二次元俚语隐语的另一套仅仅几十兆的“萌娘外挂”贴片。它在下一个秒钟又会顺带滑稽表情包连字地开始向你连滚带爬着抛出二次元软萌大段极柔话术。
这才是属于普通老百姓草根平民开发者手里拿着的这件强大的工具最为锋利的核心优势:同一个昂贵笨重的百亿参数巨核底座,依靠在周身肆意低成本轻便灵活切换外挂模块,以此低开销海量大面积复用地来伺候并支配成千上万个截然不同挑剔细分专职的下游碎裂长尾任务端口!
4. 白嫖的极致炼金术:模型合并 (Model Merging)
当你用 LoRA 炼出了一个极强的“法务专家模型A”,而你的朋友炼出了一个同基座的“幽默讽刺大王模型B”时,如何把这两个逆天的特性融合在一起?还要再重新把两份数据倒在一起花几天几夜的电费去炼一次吗? 绝对不用。 这就是开源界最新的黑暗邪道——不需消耗一滴训练算力的模型合并(Model Merging)。
依托于极客手搓的神器(如 MergeKit),因为底座冰块全是同源兄弟相同架构,你可以直接用单纯的加权数学代数平均等算法(例如 SLERP 或者 TIES-Merging / Task Arithmetic),在线把这两种截然不同的绝顶聪慧 LoRA 挂件在参数层面上直接“加减乘除”生硬且神奇地死死缝合拍扁揉碎成一体!
零训练算力投入,一瞬间你就得到了一个**“幽默且腹黑的法律学界罗翔老师复合”**。
这正是让开源 AI 像病毒一般疯狂自交配繁衍的终极密码狂欢。
下一章预告: 经过了 SFT 与神奇无比的极速轻灵低阻力 LoRA 切皮微调,这匹马终于彻底套上了听话顺拐的精准缰绳指令,甚至被极致特化成了某个特定领域的专精大师。 但是,一头只知道机械死守着按照死剧本盲目低头吐词拼命背书的野兽,它能判断残忍无情深渊里的恶毒请求吗?如果有人引诱着它教如何制作毒药,它也会乖巧尽职且满头大汗地列出那套剧毒炸药的极致极高纯度合成参数配方指南大全吗?
当能力已经齐备到溢出,接下来便是幽深且让人深陷的“道德地狱深渊法庭”的宣判调教时间。 欢迎亲临这终极一道极寒把关防线大闸门,来领略决定模型出厂生死的至高价值观审查重镇:6.4 价值观对齐:RLHF与DPO算法原理。